


ChatGPTやGeminiなどブラウザやWebAPIからアクセスできるLLMサービスが沢山出てきましたが、それらを使うには制限があったりや料金がかかったりします。その分精度が高くメリットも十分にありますが、より自由に使いたかったり、テストとして雑に使うのには億劫になってしまいます。そうなるとローカル環境でLLMを動かしたいという欲求が出てくるものです。
幸いなことにオープンになっているLLMモデルも高品質になってきており、ローカルの環境でも構築しやすいツールが出てきました。そこで今回はOllamaを使用してローカル環境で簡単にLLMを動かしてみようと思います。
インストール
今回はM1 MacbookProで作業していきます。まずはOllama公式サイトにアクセスして”Download”の項目からアプリケーションをダウンロードします。ダウンロードしたzipファイルを展開して、出てきたファイルをAPPディレクトリに移動、移動したアプリケーションを起動すると”Install”のボタンが出てくるので押すと端末から”ollama”コマンドが使えるようになります。これでインストールは完了です。
次に、使用するLLMモデルを読み込みます。有名ないくつかのモデルはOllamaで簡単に読み込めるようになっていて、対象のモデルは公式サイトで一覧になっています。また、読み込むためのコマンドは各モデルの詳細ページで確認することができます。例えばPhi3というモデルであれば、Phi3の詳細ページから`ollama run phi3`と確認できます。
また各モデルのバージョンを指定することもできます。その場合はモデル名の後ろにバージョンを指定します。例えばGemmaの7B版であれば実行コマンドは`ollama run gemma:7b`となります。このコマンドもモデルの詳細ページからバージョンを選択すると画面内に表示されるのでそのままコピペすることができます。
他にも、マルチモーダルモデルやEmbeddingモデルもあるようです。さらにコマンド実行中にはAPIが生えるのでcurlなどから叩くこともできます。さらにさらにOllama関係のライブラリを入れることでNode.jsからも簡単に使うことができます。このライブラリはOpenAIのAPIと互換性があるとのことで使い勝手が良さそうです。これらもいつか試してみようと思います。
実践
ではさっそく使ってみます。まずはターミナル上で確認します。実行するコマンドは先程登場した`ollama run gemma:7b`でGemmaの7Bモデルを使用します。このコマンドを実行すると自動的にモデルのダウンロードが開始されます。ダウンロードが完了すると自動的にチャットが始まりAIとのやり取りを始めることができます。
実行結果は下記のとおりです。コマンド一つでチャットが始まるのでとても簡単でした。ちなみに、やり取りを終えたいときは”/bye”と入力するとプログラムが終了します。
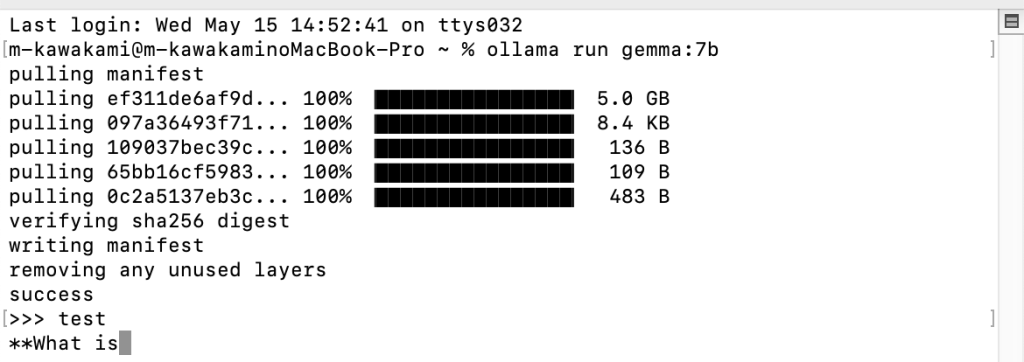
この状態でもチャットはできますがGUIの方が操作しやすいので、次にチャットUIから使用してみます。チャットUIには、よく使われている”Open WebUI”を使用します。Open WebUIはChatGPTライクなインターフェースで、ファイルや音声での入力も可能です。今回はこれをDockerで動かしブラウザからアクセスできるようにします。
% docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama % docker run -d -p 3000:8080 --env WEBUI_AUTH=False --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
上記のコマンドを実行しブラウザからアクセスすると少し前のChatGPTのようなUIのページが表示されます。
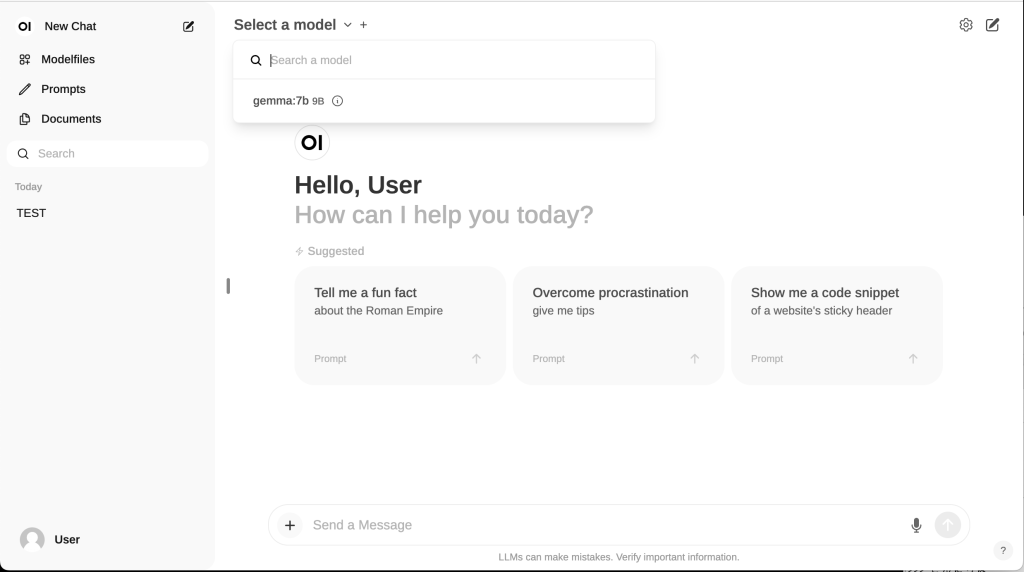
ページが表示されたら画面左上あたりにある”Select a model”から使用するモデルを選択します。あとは普通のチャットのように入力することでAIとチャットすることができます。またモデルを選択するときに+マークから複数のモデルを選択することができ、その場合はそれらのモデルへ同時にメッセージを送ることができます。
Dockerから呼び出すだけでこちらも簡単にチャットまでたどり着いてしまいました。これら便利なツールの開発者たちには頭が上がりません。
終わりに
今回はローカル環境でLLMを動かすという内容を扱ってきました。ローカル環境でも精度が上がり必要なスペックが下がっている昨今のローカルLLM界隈をみていると今後も期待大です。これからも引き続き追っていきたいと思います。
















